As organizations mature, they develop more tools. At Google, we continually create new external and internal services, as well as infrastructure to support these services. By 2013, we started outgrowing the simple automation workflows we used to update and maintain our services. Each service required complex update logic, and had to sustain infrastructure changes, frequent cluster turnups and turndowns, and more. The workflows for configuring multiple, interacting services were becoming hard to maintain— when they even existed. We needed a new solution to keep pace with the growing scale and variety of configurations involved. In response, we developed a declarative automation system that acts as a unified control plane and replaces workflows for these cases. This system consists of two main tools: Prodspec, a tool to describe a service’s infrastructure, and Annealing, a tool that updates production to match the output of Prodspec. This article discusses the problems we had to solve and the architectural choices we made along the way.
Tag Archives: infrastructure
Google Cloud Platform Blog: Google Compute Engine uses Live Migration technology to service infrastructure without application downtime
What’s remarkable about April 7th, 2014 isn’t what happened that day. It’s what didn’t.
That was the day the Heartbleed bug was revealed, and people around the globe scrambled to patch their systems against this zero-day issue, which came with already-proven exploits. In other public cloud platforms, customers were impacted by rolling restarts due to a requirement to reboot VMs. At Google, we quickly rolled out the fix to all our servers, including those that host Google Compute Engine. And none of you, our customers, noticed. Here’s why.
We introduced transparent maintenance for Google Compute Engine in December 2013, and since then we’ve kept customer VMs up and running as we rolled out software updates, fixed hardware problems, and recovered from some unexpected issues that have arisen. Through a combination of datacenter topology innovations and live migration technology, we now move our customers running VMs out of the way of planned hardware and software maintenance events, so we can keep the infrastructure protected and reliable—without your VMs, applications or workloads noticing that anything happened.
Securing Clouds
Notes on “Lessons Learned from Securing Google and Google Cloud” talk by Neils Provos
Summary
- Defense in Depth at scale by default
- Protect identities by default
- Protect data across full lifecycle by default
- Protect resources by default
- Trust through transparency
- Automate best practices and prevent common mistakes at scale
- Share innovation to raise the bar, support and invest in the security community.
- Address common cases programmatically
- Empower customers to fulfill their security responsibilities
- Trust and security can be the accelerant
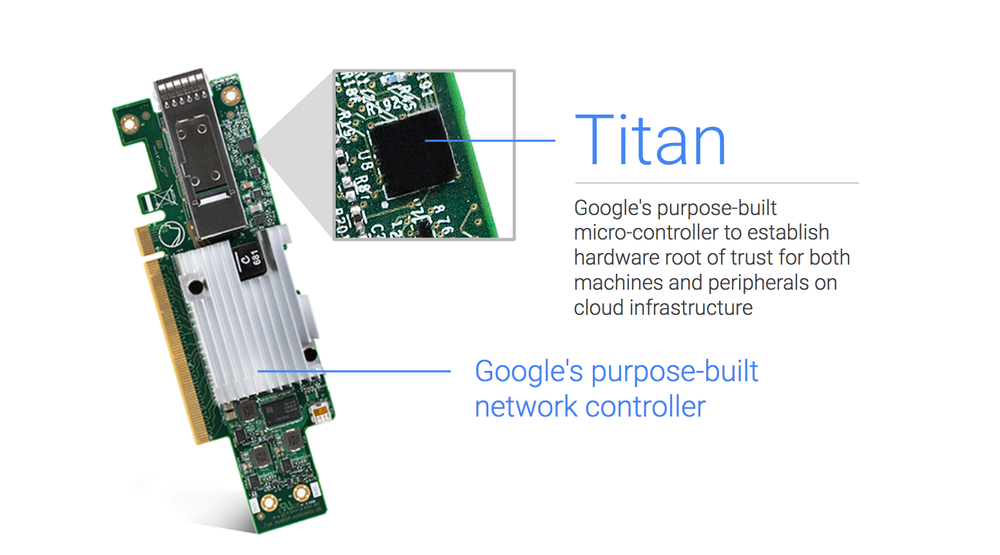
Titan: a custom TPM and more
I listened to a podcast and cut out the chit-chat, so you don’t have to:
Titan is a tiny security co-processing chip used for encryption, authentication of hardware, authentication of services.
Purpose
Every piece of hardware in google’s infrastructure can be individually identified and cryptographically verified, and any service using it mutually authenticates to that hardware. This includes servers, networking cards, switches: everything. The Titan chip is one of the ways to accomplish that.
The chip certifies that hardware is in a trusted good state. If this verification fails, the hardware will not boot, and will be replaced.
Every time a new bios is pushed, Titan checks that the code is authentic Google code before allowing it to be installed. It then checks each time that code is booted that it is authentic, before allowing boot to continue.
‘similar in theory to the u2f security keys, everything should have identity, hardware and software. Everything’s identity is checked all the time.’
Suggestions that it plays important role in hardware level data encryption, key management systems, etc.
Hardware
Each chip is fused with a unique identifier. Done sequentially, so can verify it’s part of inventory sequence.
Three main functions: RNG, crypto engine, and monotonic counter. First two are self-explanatory. Monotonic counter to protect against replay attacks, and make logs tamper evident.
Sits between ROM and RAM, to provide signature valididation of the first 8KB of BIOS on installation and boot up.
Production
Produced entirely within google. Design and process to ensure provenance. Have used other vendor’s security coprocessors in the past, but want to ensure they understand/know the whole truth.
Google folks unaware of any other cloud that uses TPMs, etc to verify every piece of hardware and software running on it.
Lessons learned from B4, Google’s SDN WAN
Google’s B4 wide area network was first revealed several years ago. The outside observer might have thought, “Google’s B4 is finished. I wonder what they’re going to do next.” Turns out, once any network is in production @scale, there’s a continued need to make it better. Subhasree Mandal covered the reality of how Google iterated multiple times on different parts of B4 to improve its performance, availability, and scalability. Several of the challenges and solutions that Subhasree detailed were definitely at the intersection of networking and distributed systems. B4 was covered in a SIGCOMM 2013 paper from Google.
No shard left behind: APIs for massive parallel efficiency
Apache Beam (incubating) is a unified batch and streaming data processing programming model that is efficient and portable. Beam evolved from a decade of system-building at Google, and Beam pipelines run today on both open source (Apache Flink, Apache Spark) and proprietary (Google Cloud Dataflow) runners. This talk will focus on I/O and connectors in Apache Beam, specifically its APIs for efficient, parallel, adaptive I/O. Google will discuss how these APIs enable a Beam data processing pipeline runner to dynamically rebalance work at runtime, to work around stragglers, and to automatically scale up and down cluster size as a job’s workload changes. Together these APIs and techniques enable Apache Beam runners to efficiently use computing resources without compromising on performance or correctness. Practical examples and a demonstration of Beam will be included.
Securing our pipes
With thousands of services communicating with each other across the globe within the Facebook network, encryption becomes a necessity. The infra should make this transparent to the service owner with minimal impacts to performance without sacrificing reliability. This talk discusses technical solutions to encryption at Facebook for Thrift microservices and compares different approaches we’ve deployed including Kerberos and TLS. We’ve made several tradeoffs between security, reliability and performance to make encryption scale to thousands of services and hundreds of thousands of hosts, with some key optimizations that make this possible.
Networking @ Google
This talk will present a high level view of Network efforts at Google including datacenters, cloud, and content delivery. It will then move into more detail on the issue of content delivery and how Google builds and operates its CDN infrastructure.
Spanner, TrueTime & The CAP Theorem
Spanner is Google’s highly available global SQL database [CDE+12]. It manages replicated data at great
scale, both in terms of size of data and volume of transactions. It assigns globally consistent real-time
timestamps to every datum written to it, and clients can do globally consistent reads across the entire
database without locking.
Source: https://cloud.google.com/spanner/docs/whitepapers/SpannerAndCap.pdf
Trusted computing from boot to cluster (CoreOS blogpost)
Trusted computing refers to a set of technologies that allow a computer to demonstrate that it is trustworthy. The definition of trustworthy is not fixed – different people will have different ideas as to what is trustworthy, and the technology does nothing to enforce a particular idea. This policy-free mechanism is implemented with the aid of an additional hardware component on the system motherboard, a Trusted Platform Module (TPM).
TPMs are capable of certain operations that make trusted computing possible. They can generate cryptographic keys, and they can sign things with these keys. They can store a “measurement” of system state, and can communicate that measurement to a remote system through a cryptographically secure channel. And they are capable of encrypting small secrets and sealing them to a specific measurement state.
The trusted computing implementation in Tectonic and CoreOS takes advantage of all of these features to establish trust of individual CoreOS machines. Our implementation is “distributed” because of the ability to extend the chain of trust into the cluster, which creates an industry-first end-to-end trusted computing environment.
Source: https://coreos.com/blog/coreos-trusted-computing.html
